Qué es Jenkins
Jenkins es un servidor de automatización de código abierto escrito en Java. Con un soporte muy activo basado en la comunidad y una gran cantidad de complementos, es la herramienta más popular para implementar los procesos de Integración Continua y Entrega Continua. Anteriormente conocido como Hudson, se le cambió el nombre después de que Oracle comprara Hudson y decidiera desarrollarlo como software propietario. Jenkins permaneció bajo la licencia del MIT y es muy valorado por su simplicidad, flexibilidad y versatilidad.
Jenkins se destaca entre otras herramientas de integración continua y es el software de este tipo más utilizado. Todo eso es posible debido a sus características y capacidades.
Repasemos las partes más interesantes de las características de Jenkins.
- Independiente del lenguaje: Jenkins tiene muchos complementos, que admiten la mayoría de los lenguajes y marcos de programación. Además, dado que puede usar cualquier comando de shell y cualquier software instalado, es adecuado para todos los procesos de automatización que se puedan imaginar.
- Extensible por complementos: Jenkins tiene una gran comunidad y muchos complementos disponibles (más de 1000). También le permite escribir sus propios complementos para per lassonalizar Jenkins según sus necesidades.
- Portable: Jenkins está escrito en Java, por lo que puede ejecutarse en cualquier sistema operativo. Para mayor comodidad, también se entrega en muchas versiones: archivo de aplicación web (WAR), imagen de Docker, binario de Windows, binario de Mac y binario de Linux.
- Admite la mayoría de SCM: Jenkins se integra con prácticamente todas las herramientas de creación o administración de código fuente que existen. Nuevamente, debido a su amplia comunidad y complementos, no existe otra herramienta de integración continua que admita tantos sistemas externos.
- Distribuido: Jenkins tiene un mecanismo incorporado para el modo maestro/esclavo, que distribuye sus ejecuciones en varios nodos ubicados en varias máquinas. También puede usar un entorno heterogéneo, por ejemplo, diferentes nodos pueden tener instalado un sistema operativo diferente. Simplicidad: El proceso de instalación y configuración es sencillo. No es necesario configurar ningún software adicional, ni la base de datos. Se puede configurar completamente a través de scripts GUI, XML o Groovy.
- Orientado a código: las canalizaciones de Jenkins se definen como código. Además, el propio Jenkins se puede configurar mediante archivos XML o scripts Groovy. Eso permite mantener la configuración en el repositorio del código fuente y ayuda en la automatización de la configuración de Jenkins.
Instalación de Jenkins con Docker
Primero hay que crear un directorio que luego enlazaremos como un volumen al correr jenkins. Hemos de cambiar el propietario de dicho directorio al usado por jenkins (uid 1000) y luego cambiar los permisos
1
2
3
4
mkdir $HOME/jenkins_home
sudo chown 1000 $HOME/jenkins_home
sudo chmod 777 $HOME/jenkins_home
docker run -d -p 49001:8080 -v $HOME/jenkins_home:/var/jenkins_home --name jenkins jenkins/jenkins:lts-jdk11
Visitamos la url http://localhost:49001/ y nos pedirá la contraseña de administrador que se puede recuperar con el comando docker logs jenkins o haciendo un cat del archivo $HOME/jenkins_home/secrets/initialAdminPassword
A continuación aparece la ventana para seleccionar los plugins (dejaremos los sugeridos por defecto)
y nos pedirá introducir los datos del usuario administrador del sistema.
Por último, aparecerá la ventana de administración de jenkins
Jenkins hello world
Todo en el mundo de TI comienza con el ejemplo de Hello World.
Sigamos esta regla y veamos los pasos para crear la primera pipeline (nombre que se le da a las configuraciones) de Jenkins:
- Haz clic en Nuevo elemento.
- Introduce hola mundo como nombre del elemento, elige
Pipeliney haz clic en Aceptar. - Hay muchas opciones. Las omitiremos por ahora e iremos directamente a la sección Pipeline.
- Allí, en el cuadro de texto Script, podemos ingresar el script de pipeline:
New item
1
2
3
4
5
6
7
8
9
10
pipeline {
agent any
stages {
stage("Hello") {
steps {
echo 'Hello World'
}
}
}
}
- Haz clic en guardar
- Por último, elige la opción
Build now
Como resultado obtenemos la siguiente pantalla:
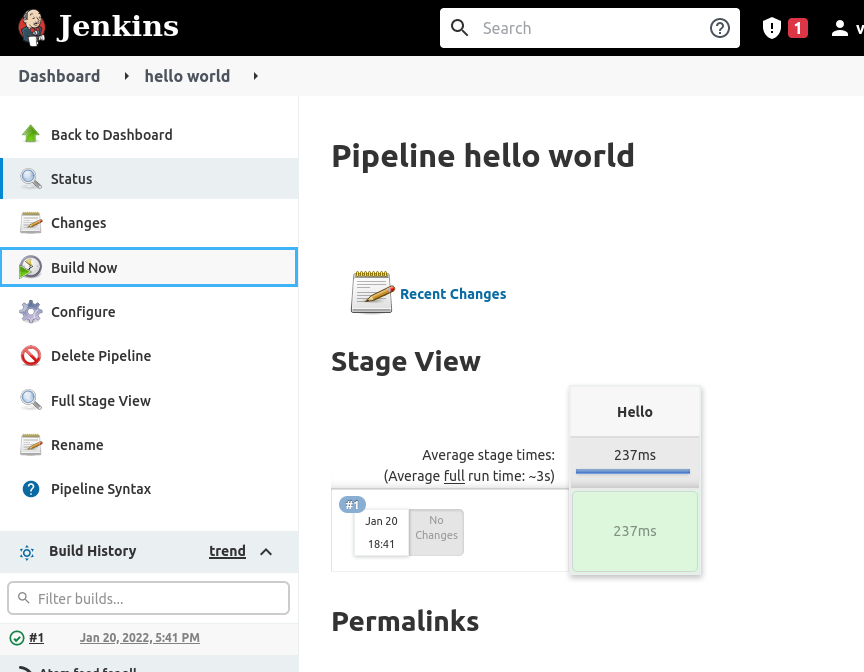
Como el resultado está en color verde significa que todo ha ido correctamente.
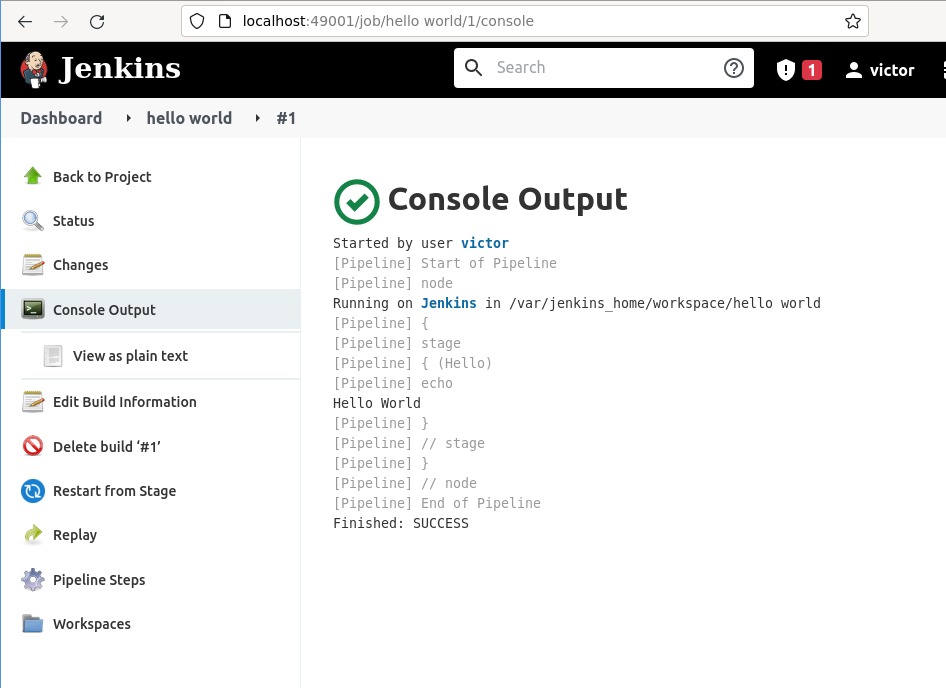
Si haces clic en

accedes a la información de este build y en el aparado Console output se ve el resultado de ejecutar el pipeline
Introducción a las pipelines
Una tubería es una secuencia de operaciones automatizadas que generalmente representa una parte de la entrega de software y el proceso de control de calidad. Puede verse simplemente como una cadena de scripts que proporciona los siguientes beneficios adicionales:
- Agrupación de operaciones: las operaciones se agrupan en etapas (stages también conocidas gates o quality gates) que introducen una estructura en el proceso y definen claramente la regla: si una etapa falla, no se ejecutan más etapas.
- Visibilidad: se visualizan todos los aspectos del proceso, lo que ayuda en el análisis rápido de fallas y promueve la colaboración en equipo
- Comentarios: los miembros del equipo se enteran de cualquier problema tan pronto como ocurre, para que puedan reaccionar rápidamente.
Estructura de una pipeline
Una pipeline de Jenkins consta de dos tipos de elementos: stages y steps. La siguiente figura muestra cómo se utilizan:
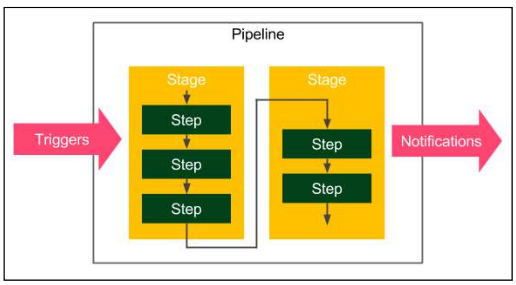
Los siguientes son los elementos básicos de la canalización:
- Step: una sola operación (le dice a Jenkins qué hacer, por ejemplo, retirar el código del repositorio, ejecutar un script)
- Stage: una separación lógica de pasos (agrupa secuencias de pasos conceptualmente distintas, por ejemplo, compilar, probar e implementar) que se utiliza para visualizar el progreso de la canalización de Jenkins.
Para continuar con el ejemplo vamos a extender la pipeline hello world para que tenga más de un stage
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pipeline {
agent any
stages {
stage('First Stage') {
steps {
echo 'Step 1. Hello World'
}
}
stage('Second Stage') {
steps {
echo 'Step 2. Second time Hello'
echo 'Step 3. Third time Hello'
}
}
}
}
Como resultado de esta pipeline obtendremos la siguiente representación visual:
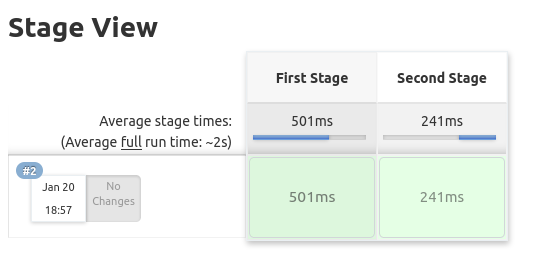
Y esta es la salida de la consola

Commit pipeline
El proceso de Integración Continua más básico se llama commit pipeline. Esta fase clásica, como su nombre lo dice, comienza con un commit (o push en Git) al repositorio principal y da como resultado un informe sobre el éxito o el fracaso de la compilación. Ya que se ejecuta después de cada cambio en el código, la construcción debe tomar no más de 5 minutos y debe consumir una cantidad razonable cantidad de recursos. La fase de confirmación es siempre el punto de partida del proceso de Entrega Continua, y proporciona el ciclo de retroalimentación más importante en el proceso de desarrollo, información constante si el código está en
un estado saludable.
La fase de compromiso funciona de la siguiente manera. Un desarrollador comprueba en el código al repositorio, la Integración Continua detecta el cambio en el servidor y se inicia la compilación.
Consta de 3 etapas:
-
Checkout En esta etapa se descarga el código desde el repositorio
-
Compile Esta etapa compila el código fuente
-
Test unit Esta etapa corre una serie de test unitarios
Vamos a crear un proyecto de ejemplo que implemente commit pipeline
Este ejemplo es para un proyecto que usa Git, Java, Gradle y Spring Boot, pero lo mismo aplica para otras tecnologías
Checkout
Chequear el código del repositorio es siempre la primera operación en una pipeline. Para ello nos hemos de crear un repositorio llamado calculator. Cuidado que hay que añadir un archivo README.md porque de lo contrario el proyecto está vacío y no lo chequea.
Ahora tendremos un repo en https://github.com/nombre-de-usuario/calculator.git
Creación de la etapa Checkout
Vamos a crear una nueva pipeline llamada calculator y en script introducir el siguiente código:
1
2
3
4
5
6
7
8
9
10
pipeline {
agent any
stages {
stage("Checkout") {
steps {
git url: 'https://github.com/victorponz/calculator'
}
}
}
}
Nota Si la rama no es
masterhay que configurarlo así:
La pipeline puede ser ejecutada por cualquier agente y su único paso es descargar el código del repositorio. Podemos hacer clic en Build Now y comprobar si se ha ejecutado correctamente.
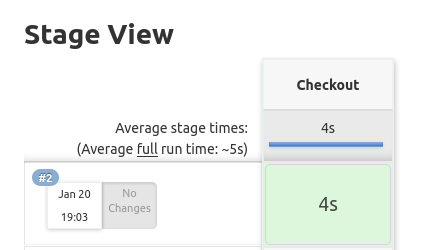
Ahora ya podemos realizar la segunda fase.
Compilar
Para compilar un proyecto hemos de:
- Crear un proyecto con el código fuente
- Hacer un
pushal repositorio - Añadir la etapa
Compilara la pipeline
Crear un proyecto Java Spring Boot
Vamos a crear un proyecto simple de java usando gradle como framework de construcción.
Spring Boot es un framework de Java que simplifica la creación de aplicaciones empresariales. Gradle es un sistema de automatización de compilación que se basa en los conceptos de Apache Maven.
La forma más sencilla de crear un proyecto Spring Boot es realizar los siguientes pasos:
- Visitamos a la página http://start.spring.io/.
- Seleccionamos el proyecto Gradle en lugar del proyecto Maven.
- Rellenamos
GroupyArtifact(por ejemplo,com.victorponzycalculator). - Agregar
Weba Dependencias. - Hacemos clic en Generar proyecto.
- El esqueleto del programa generado debe descargarse (el archivo calculator.zip).
GIT
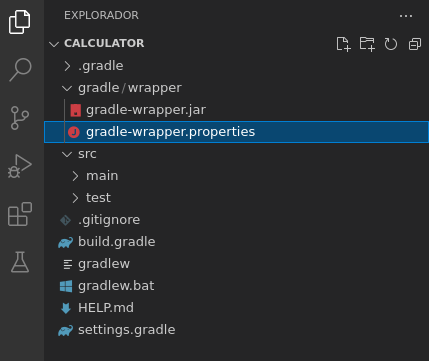
Clonamos el repositorio en local y movemos todos los archivos dentro de la carpeta del mismo con cuidado de seleccionar también los archivos ocultos
Esta será la estructura de archivos y directorios:
En el archivo build.gradle modificamos la línea
1
id 'org.springframework.boot' version '2.6.3'
por
1
id 'org.springframework.boot' version '2.6.2'
ya que en el momento de elaboración de estos apuntes no encuentra la versión 2.6.3
Ahora podemos compilar el proyecto localmente con los comandos:
1
./gradlew compileJava

GIT
Creación de la etapa de compilación
Ahora ya podemos crear la etapa de compilación
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
pipeline {
agent any
stages {
stage('Checkout') {
steps {
git url: 'https://github.com/victorponz/calculator'
}
}
stage('Compile') {
steps {
sh "./gradlew compileJava"
}
}
}
}
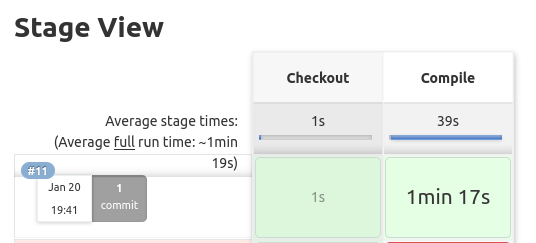
Usamos exactamente el mismo comando localmente y en la pipeline de Jenkins, lo cual es una muy buena señal porque el proceso de desarrollo local es coherente con el entorno de integración continua. Después de ejecutar la compilación, veremos dos cuadros verdes. También se puede verificar que el proyecto se compiló correctamente en el registro de la consola.
Test unitario (unit test)
Es hora de agregar la última etapa que es la prueba unitaria, que verifica si nuestro código hace lo que esperamos que haga. Tenemos que:
- Agregar el código fuente para la lógica de la calculadora
- Escribir prueba unitaria para el código.
- Agregar una etapa para ejecutar la prueba unitaria
Creación de la lógica de negocio
La primera versión de la calculadora podrá sumar dos números. Agregamos la lógica empresarial como una clase en el archivo src/main/java/com/victorponz/calculator/Calculator.java:
1
2
3
4
5
6
7
8
9
package com.victorponz.calculator;
import org.springframework.stereotype.Service;
@Service
public class Calculator {
int sum(int a, int b) {
return a + b;
}
}
Para ejecutar la lógica empresarial, también debemos agregar el controlador de servicio web en un archivo separado src/main/java/com/victorponz/calculator/CalculatorController.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package com.victorponz.calculator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
class CalculatorController {
@Autowired
private Calculator calculator;
@RequestMapping("/sum")
String sum(@RequestParam("a") Integer a,
@RequestParam("b") Integer b) {
return String.valueOf(calculator.sum(a, b));
}
}
Esta clase expone la lógica empresarial como un servicio web. Podemos ejecutar la aplicación y ver cómo funciona:
1
./gradlew bootRun
Debería iniciar nuestro servicio web y podemos verificar que funciona navegando al navegador y abriendo la página http://localhost:8080/sum?a=1&b=2. Esto debería sumar dos números ( 1 y 2) y mostrar 3 en el navegador.
Crear un test unitario
Ya tenemos la aplicación de trabajo. ¿Cómo podemos asegurarnos de que la lógica funcione como se espera? Lo hemos probado una vez, pero para saber constantemente, necesitamos una prueba unitaria. En nuestro caso, será trivial, quizás incluso innecesario; sin embargo, en proyectos reales, las pruebas unitarias pueden evitar errores y fallos del sistema.
Vamos a crear una prueba unitaria en el archivo:
src/test/java/com/victorponz/calculator/CalculatorApplicationTest.java:
1
2
3
4
5
6
7
8
9
10
11
12
package com.victorponz.calculator;
import org.junit.Test;
import static org.junit.Assert.assertEquals;
public class CalculatorApplicationTest {
private Calculator calculator = new Calculator();
@Test
public void testSum() {
assertEquals(5, calculator.sum(2, 3));
}
}
Modificar el archivo build.gradle modificándolo para que la parte dependencies y tasks.named queden así:
1
2
3
4
5
6
7
8
9
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'junit:junit:4.13'
}
tasks.named('test') {
useJUnit()
}
Podemos ejecutar la prueba localmente usando el comando de prueba ./gradlew test.
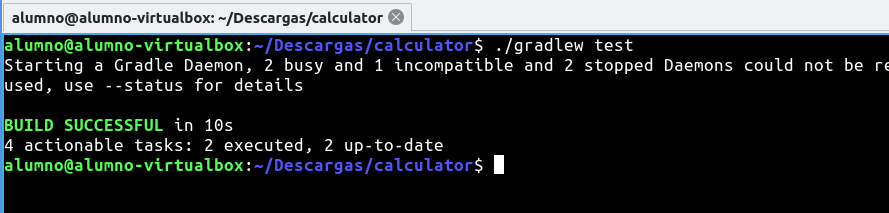
Si creamos otro test para que nos dé un error, por ejemplo
1
2
3
4
@Test
public void testSumIncorrecto() {
assertEquals(7, calculator.sum(2, 3));
}
Nos dará un error que podemos comprobar en el fichero file:///home/alumno/Documentos/calculator/build/reports/tests/test/index.html
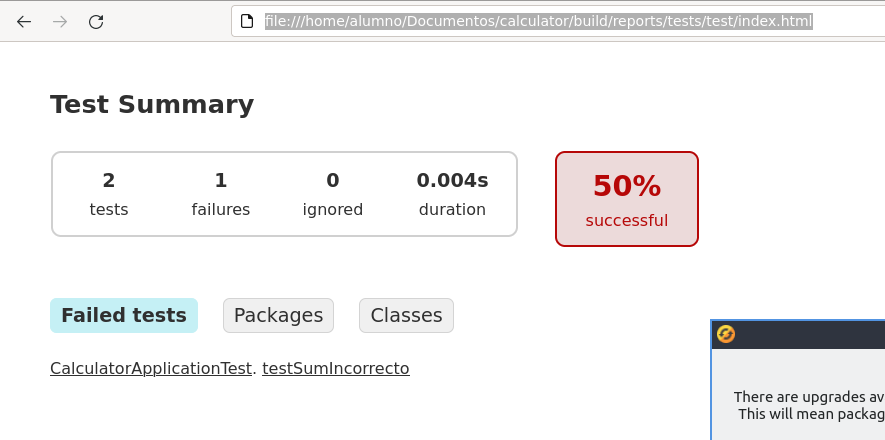
Importante
Eliminad el test incorrecto
Luego, confirmemos el código y lo subimos al repositorio:
1
2
3
git add .
git commit -m "Añadir suma, controlado y test unitario"
git push
Creación de la etapa de testeo
Ahora podemos añadir una etapa de testeo:
1
2
3
4
5
stage("Unit test") {
steps {
sh "./gradlew test"
}
}
Cuando volvamos a construir la pipeline, deberíamos ver tres cuadros, lo que significa que hemos completado la pipeline de integración continua.
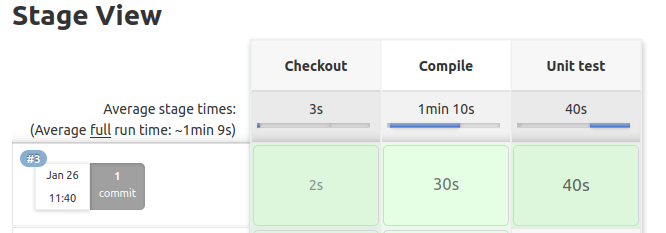
Jenkinsfile
Todo el tiempo, hasta ahora, creamos el código de la pipeline directamente en Jenkins. Sin embargo, esta no es la única opción. También podemos poner la definición de la pipeline dentro de un archivo llamado Jenkinsfile y enviarlo al repositorio junto con el código fuente. Este método es aún más consistente porque la apariencia de la pipeline está estrictamente relacionada con el proyecto en sí.
Este enfoque trae beneficios inmediatos, como sigue:
- En caso de fallo de Jenkins, la definición de pipeline no se pierde (porque está almacenada en el repositorio de código, no en Jenkins)
- El historial de cambios en la pipeline se almacena
- Los cambios en la pipeline pasan por el proceso de desarrollo de código estándar (por ejemplo, están sujetos a revisiones de código)
- El acceso a los cambios en la pipeline está restringido exactamente de la misma manera que el acceso al código fuente.
Crear Jenkinsfile
Podemos crear el archivo Jenkins y enviarlo a nuestro repositorio de GitHub. Su contenido es casi el mismo que el canal de confirmación que escribimos. La única diferencia es que la etapa de verificación se vuelve redundante porque Jenkins primero tiene que verificar el código (junto con Jenkinsfile) y luego leer la estructura de canalización (de Jenkinsfile). Esta es la razón por la que Jenkins necesita conocer la dirección del repositorio antes de leer el archivo Jenkins.
Vamos a crear un archivo llamado Jenkinsfile en el directorio raíz de nuestro proyecto:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
pipeline {
agent any
stages {
stage("Compile") {
steps {
sh "./gradlew compileJava"
}
}
stage("Unit test") {
steps {
sh "./gradlew test"
}
}
}
}
Ahora subimos los cambios al repositorio:
1
2
3
git add .
git commit -m "Añadido Jenkinsfile"
git push
Ejecutar la pipeline con Jenkinsfile
Cuando Jenkinsfile está en el repositorio, todo lo que tenemos que hacer es abrir la configuración de la pipeline y en la sección Pipeline:
Cambiar definición de secuencia pipeline script a pipeline script from SCM
- Seleccionamos Git en SCM
- Ponemos https://github.com/victorponz/calculator.git en la URL del repositorio
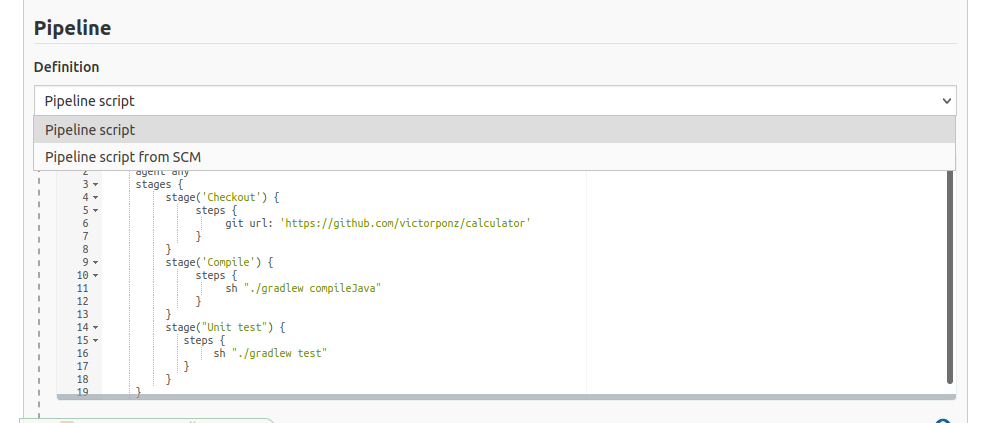
El resultado debe ser este
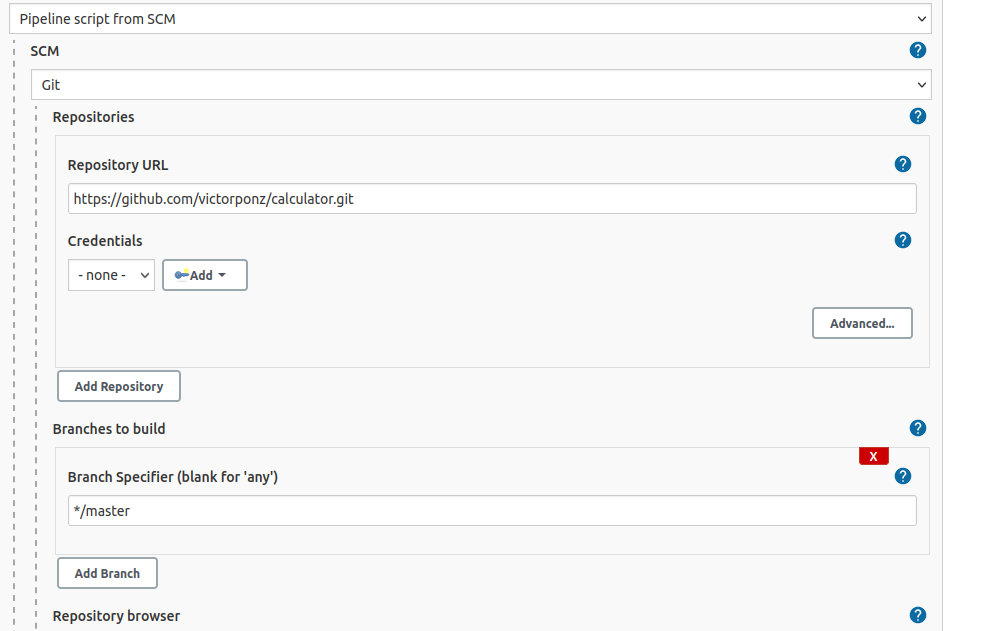
Cuidado con la rama que puede ser
main
Después de guardar, la compilación siempre se ejecutará desde la versión actual de Jenkinsfile en el repositorio.
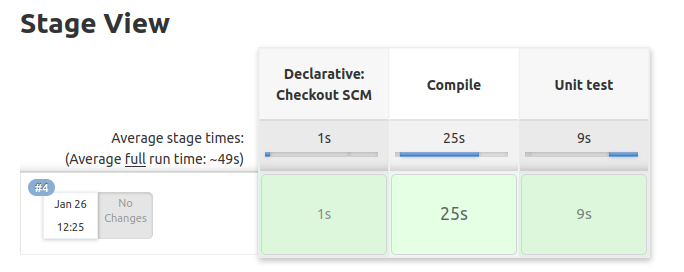
Etapas de calidad de código
Podemos ampliar los tres pasos clásicos de la integración continua con pasos adicionales. Los más utilizados son la cobertura de código y el análisis estático. Veamos cada uno de ellos.
Cobertura de código
Según la Wikipedia
La cobertura de código es una medida (porcentual) en las pruebas de software que mide el grado en que el código fuente de un programa ha sido comprobado con pruebas de software. Sirve para determinar la calidad del test que se lleve a cabo y para determinar las partes críticas del código que no han sido comprobadas y las partes que ya lo fueron, además se puede utilizar como técnica de optimización dentro de un compilador optimizador para llevar a cabo una eliminación de código muerto, más específicamente sirve para detectar código inalcanzable
Piensa en el siguiente escenario: tienes un proceso de integración continua bien configurado; sin embargo, nadie en su proyecto escribe pruebas unitarias. Pasa todas las compilaciones, pero no significa que el código funcione como se esperaba. ¿Qué hacer entonces? ¿Cómo asegurar que el código sea probado?
La solución es agregar la herramienta de cobertura de código que ejecuta todas las pruebas y verifica qué partes del código se han ejecutado. Luego, crea un informe que muestra las secciones no probadas. Además, podemos hacer que la compilación falle cuando hay demasiado código sin probar.
Hay muchas herramientas disponibles para realizar el análisis de cobertura de prueba; para Java, los más populares son JaCoCo, Clover y Cobertura.
Usemos JaCoCo y mostremos cómo funciona la verificación de cobertura en la práctica. Para ello, debemos realizar los siguientes pasos:
- Agregamos
JaCoCoa la configuración deGradle. - Agregue la etapa de cobertura de código a la pipeline./
- Opcionalmente, publicamos los informes de
JaCoCoen Jenkins.
Añadir JaCoCo a Gradle
Para poder ejecutar JaCoCo en Gradle, necesitamos agregar el complemento jacoco al archivo build.gradle agregando la siguiente línea en la sección del plugin:
1
apply plugin: "jacoco"
A continuación, si deseamos que Gradle falle en caso de una cobertura de código demasiado baja, también podemos agregar la siguiente configuración al archivo build.gradle:
1
2
3
4
5
6
7
8
9
jacocoTestCoverageVerification {
violationRules {
rule {
limit {
minimum = 0.2
}
}
}
}
Esta configuración establece la cobertura de código mínima en un 20 %. Podemos ejecutarlo con el siguiente comando:
1
./gradlew test jacocoTestCoverageVerification
El comando verifica si la cobertura del código es al menos del 20%. Podemos jugar con el valor mínimo para ver el nivel en el que falla la compilación. También podemos generar un informe de cobertura de prueba usando el siguiente comando:
1
./gradlew test jacocoTestReport
Que genera un informe en build/reports/jacoco/test/html/index.html
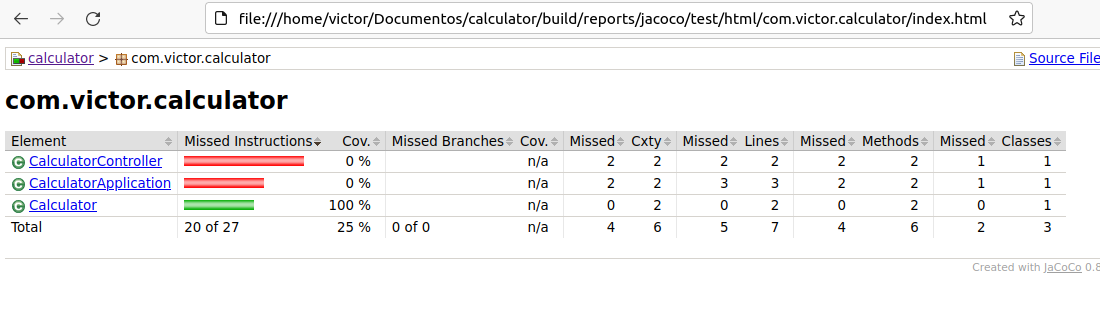
Añadir una etapa de cobertura de código
Es tan sencillo como añadir lo siguiente al archivo Jenkinsfile
1
2
3
4
5
6
stage("Code coverage") {
steps {
sh "./gradlew jacocoTestReport"
sh "./gradlew jacocoTestCoverageVerification"
}
}
A partir de ahora, si alguien hace un commit de código que no está bien cubierto con test, el proceso de build falla.
Publicar el informe de cobertura de código
Cuando la cobertura es baja y la pilelin falla, sería útil mirar el informe de cobertura de código y encontrar qué partes aún no están cubiertas con las pruebas. Podríamos ejecutar Gradle localmente y generar el informe de cobertura; sin embargo, es más conveniente que Jenkins nos muestre el informe.
Para publicar el informe de cobertura de código en Jenkins, necesitamos la siguiente definición de etapa:
1
2
3
4
5
6
7
8
9
10
11
stage("Code coverage") {
steps {
sh "./gradlew jacocoTestReport"
publishHTML (target: [
reportDir: 'build/reports/jacoco/test/html',
reportFiles: 'index.html',
reportName: "JaCoCo Report"
])
sh "./gradlew jacocoTestCoverageVerification"
}
}
Esta etapa copia el informe JaCoCo generado en la salida de Jenkins. Cuando volvamos a ejecutar la compilación, deberíamos ver un enlace a los informes de cobertura de código (en el menú del lado izquierdo, debajo de “Build Now”).
Nota
Debemos instalar el plugin
HTML Publish
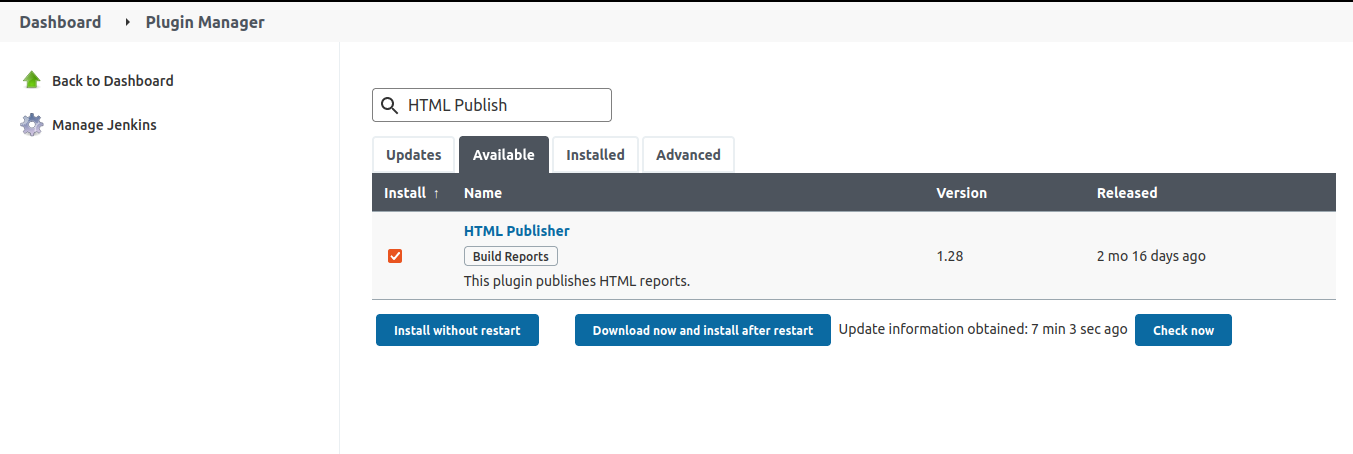
Al ejecutar la pipeline comprobamos que da errror:
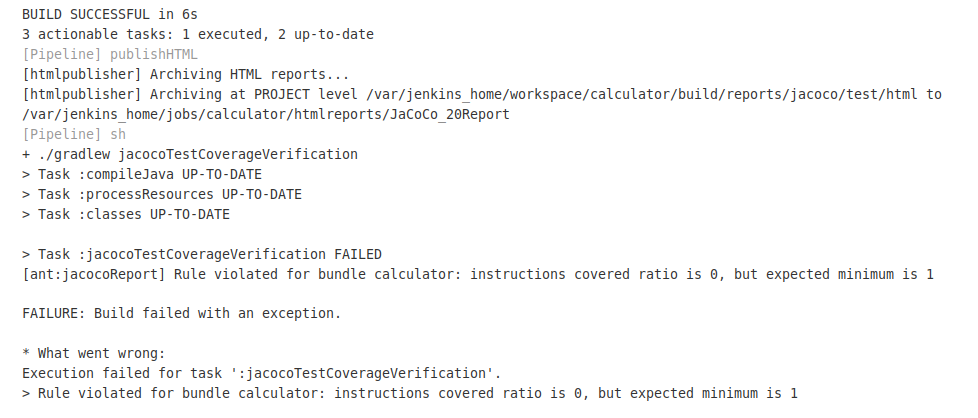
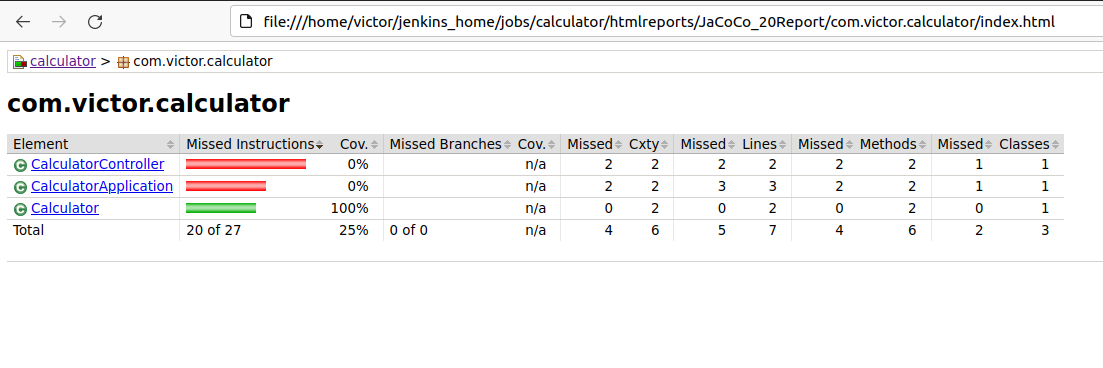
Y este es el informe guardado en file:///home/victor/jenkins_home/jobs/calculator/htmlreports/JaCoCo_20Report/com.victor.calculator/index.html
 Si modificamos
Si modificamos build.gradle y volemos a dejar la cobertura al 0,2 veremos que ya pasa el test:
Análisis estático de código
El código puede funcionar perfectamente bien, sin embargo, ¿qué pasa con la calidad del código en sí? ¿Cómo nos aseguramos de que sea mantenible y esté escrito en un buen estilo?
El análisis de código estático es un proceso automático de verificar el código sin ejecutarlo realmente. En la mayoría de los casos, implica verificar una serie de reglas en el código fuente. Estas reglas pueden aplicarse a una amplia gama de aspectos; por ejemplo, todas las clases públicas deben tener un comentario de Javadoc; la longitud máxima de una línea es de 120 caracteres, o si una clase define el método equals(), también debe definir el método hashCode().
Las herramientas más populares para realizar el análisis estático del código Java son Checkstyle, FindBugs y PMD. Veamos un ejemplo y agreguemos la etapa de análisis de código estático usando Checkstyle. Lo haremos en tres pasos:
- Agregamos la configuración Checkstyle.
- Agregamos la etapa Checkstyle.
- Opcionalmente, publicamos el informe Checkstyle en Jenkins.
Añadir la configuración Checkstyle
Para agregar la configuración de Checkstyle, necesitamos definir las reglas contra las cuales se verifica el código. Podemos hacer esto especificando el archivo config/checkstyle/checkstyle.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<?xml version="1.0"?>
<!DOCTYPE module PUBLIC "-//Checkstyle//DTD Checkstyle Configuration 1.3//EN" "https://checkstyle.org/dtds/configuration_1_3.dtd">
<module name="Checker">
<property name="charset" value="UTF-8" />
<property name="severity" value="error" />
<!-- Checks for whitespace -->
<!-- See http://checkstyle.org/config_whitespace.html -->
<module name="FileTabCharacter">
<property name="eachLine" value="true" />
</module>
</module>
La configuración contiene solo una regla: verificar que no se han introducido tabuladores en el código. Si hay, la compilación falla.
También necesitamos agregar el complemento checkstyle al archivo build.gradle:
1
apply plugin: 'checkstyle'
Luego, podemos ejecutar el estilo de verificación con el siguiente código:
1
./gradlew checkstyleMain
El documento generado se encuentra en file:///home/victor/Documentos/calculator/build/reports/checkstyle/main.html
Y este es el contenido
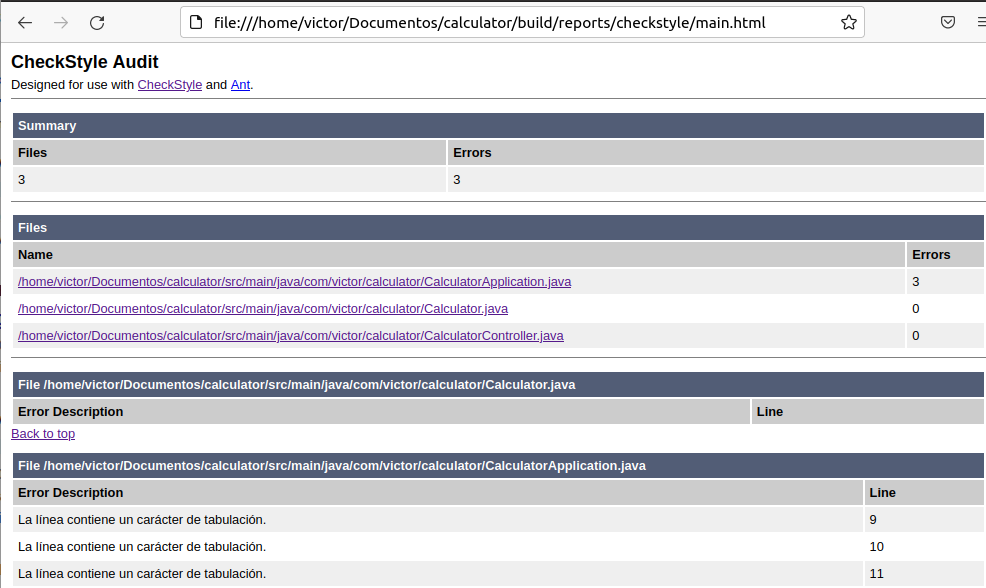
Añadir una etapa de análisis estático
Como antes, vamos a añadir la etapa de análisis estático en el archivo Jenkinsfile
1
2
3
4
5
stage("Static code analysis") {
steps {
sh "./gradlew checkstyleMain"
}
}
Ahora cada vez que alguien realice un commit con tabuladores, la construcción del código fallará.
Publicando el informe
Al igual que con JaCoCo, podemos publicar el informe en Jenkins
1
2
3
4
5
publishHTML (target: [
reportDir: 'build/reports/checkstyle/',
reportFiles: 'main.html',
reportName: "Checkstyle Report"
])
De tal forma que la etapa quedará como sigue:
1
2
3
4
5
6
7
8
9
10
stage("Static code analysis") {
steps {
sh "./gradlew checkstyleMain"
publishHTML (target: [
reportDir: 'build/reports/checkstyle/',
reportFiles: 'main.html',
reportName: "Checkstyle Report"
])
}
}
Ahora al lanzar la construcción se producirá un error
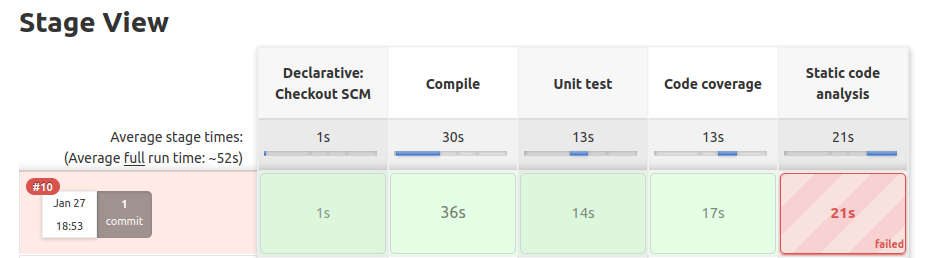
Y el informe está accesible en file:///home/victor/jenkins_home/workspace/calculator/build/reports/checkstyle/main.html
Para que la construcción sea correcta debemos eliminar los tabuladores del archivo CalculatorApplication.java
1
2
3
4
5
6
7
8
9
10
11
12
13
package com.victor.calculator;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class CalculatorApplication {
public static void main(String[] args) {
SpringApplication.run(CalculatorApplication.class, args);
}
}
Tareas
Has aprendido mucho sobre cómo configurar el proceso de integración continua. Como la práctica hace al hombre perfecto, recomendamos hacer los siguientes ejercicios:
Tarea 1
Crea un programa de Python que multiplique dos números pasados como parámetros de la línea de comandos. Agrega pruebas unitarias y publica el proyecto en GitHub:
- Crea dos archivos
calculadora.pyytest_calculator.py- Puedes usar la biblioteca
unittesten https://docs.python.org/library/unittest.html- Ejecuta el programa y la prueba unitaria.
Podéis echar un vistazo a https://www.w3schools.com/python/python_classes.asp para información de cómo crear una clase en python
Tarea 2
Crea la canalización de integración continua para el proyecto de calculadora de Python:
- Usa Jenkinsfile para especificar la canalización
- Configura el disparador para que la canalización se ejecute automáticamente en caso de cualquier commit en el repositorio
- La canalización no necesita el paso de compilación ya que Python es un lenguaje interpretable Ejecuta la canalización y observe los resultados
- Intenta comprometer el código que rompe cada etapa de la tubería y observa cómo se visualiza en Jenkins.