Introducción
El software moderno se ensambla utilizando componentes de terceros y de código abierto, pegados de forma compleja y única, e integrados con el código original para proporcionar la funcionalidad deseada. Los componentes de terceros (incluido el software con licencia comercial, el propietario y el “disponible en origen”), junto con los de código abierto, proporcionan los elementos necesarios que permiten a las organizaciones ofrecer valor, mejorar la calidad, reducir el riesgo y el tiempo de comercialización. Las ventajas del código abierto son muchas. Sin embargo, al utilizar componentes de código abierto, las organizaciones acaban asumiendo la responsabilidad del código que no han escrito. Las alianzas estratégicas entre las organizaciones y los proyectos de código abierto pueden conducir a un uso saludable del código abierto y a la reducción del riesgo en general.
El análisis de componentes es el proceso de identificación de posibles áreas de riesgo derivadas del uso de componentes de software y hardware de terceros y de código abierto. El análisis de componentes es una función dentro de un marco general de gestión de riesgos de la cadena de suministro cibernética (C-SCRM). Un subconjunto del Análisis de Componentes quhttps://docs.dependencytrack.org/e sólo se refiere al software y que tiene un alcance limitado se denomina comúnmente Análisis de la Composición del Software (SCA).
Cualquier componente que tenga el potencial de impactar negativamente en el riesgo de la cadena de suministro cibernética es un candidato para el Análisis de Componentes.
Factores de riesgo comunes
Inventario de componentes
Disponer de un inventario preciso de todos los componentes de terceros y de código abierto es fundamental para la identificación de riesgos. Sin este conocimiento, otros factores del Análisis de Componentes se vuelven impracticables de determinar con alta confianza. El uso de soluciones de gestión de dependencias y/o de la lista de materiales de software (SBOM) puede ayudar a crear el inventario.
Edad de los componentes
Los componentes pueden tener diferentes grados de criterios de aceptación de la edad. Los factores que influyen en la edad aceptable incluyen el tipo de componente, el ecosistema del que forma parte (Maven, NPM, etc.) y el propósito del componente. La antigüedad de un componente puede significar el uso de tecnología anticuada y puede tener una mayor probabilidad de ser pasado por alto por los investigadores de seguridad.
Componentes obsoletos
Las nuevas versiones de los componentes pueden mejorar la calidad o el rendimiento. Estas mejoras pueden ser heredadas por las aplicaciones que dependen de ellos. Los componentes que han llegado al final de su vida útil (EOL) o del soporte (EOS) también afectan al riesgo. Hay dos enfoques comunes para el código abierto apoyado por la comunidad:
- Apoyar la última revisión de las últimas (x) versiones - (es decir, 4.3.6 y 4.2.9)
- Apoyar sólo la última versión publicada (es decir, 4.3.6 hoy y 4.4.0 mañana)
En función de la propensión al riesgo, puede ser estratégico utilizar únicamente componentes de terceros y de código abierto que sean compatibles.
Con referencia a la terminología del Versionado Semántico, se pueden esperar cambios en la API entre versiones mayores de un componente, pero son raros entre versiones menores y parches. Los cambios en la API de un componente pueden dar lugar a tiempos de reparación más largos si los componentes no se han actualizado continuamente. Mantener los componentes actualizados puede reducir el tiempo de remediación cuando se requiere una respuesta rápida.
La identificación de las versiones obsoletas puede aprovechar los repositorios específicos del ecosistema y puede lograrse mediante el uso de gestores de dependencias o URL de paquetes. El análisis de componentes puede identificar los componentes obsoletos, así como proporcionar información sobre las versiones más nuevas.
Vulnerabilidades conocidas
Históricamente, las vulnerabilidades conocidas se referían a las entradas (CVEs) en la Base de Datos Nacional de Vulnerabilidades (NVD). La NVD describe (a través de CPE) tres tipos de componentes:
- Aplicaciones (incluye bibliotecas y frameworks)
- Sistemas operativos
- Hardware
Aunque la NVD puede ser la fuente más conocida de información sobre vulnerabilidades, no es la única. Existen múltiples fuentes públicas y comerciales de información sobre vulnerabilidades. Tener una vulnerabilidad conocida no requiere que la información sobre la vulnerabilidad esté presente en una de estas fuentes. El simple hecho de estar documentada (por ejemplo, una publicación en las redes sociales, un defecttracker, un registro de commit, notas de publicación, etc.) clasifica la vulnerabilidad como conocida.
El análisis de componentes suele identificar vulnerabilidades conocidas a partir de múltiples fuentes de información sobre vulnerabilidades.
Tipo de componente
Los marcos y las bibliotecas tienen desafíos de actualización únicos y riesgos asociados. Las abstracciones, el acoplamiento y los patrones de diseño arquitectónico pueden afectar al riesgo de utilizar un determinado tipo de componente. Por ejemplo, las bibliotecas de registro pueden estar incrustadas en una gran aplicación, pero la sustitución de las implementaciones puede ser automatizada. Del mismo modo, la sustitución de un marco de trabajo de aplicación web por un marco alternativo sería probablemente un esfuerzo de alto riesgo que llevaría a cambios arquitectónicos, regresiones y reescrituras de código. La evaluación del tipo debería formar parte de toda estrategia de análisis de componentes.
Función de los componentes
Identificar y analizar el propósito de cada componente puede revelar la existencia de componentes con funciones duplicadas o similares. Por ejemplo, es poco probable que una aplicación necesite varios analizadores XML o proveedores criptográficos.El riesgo potencial puede reducirse minimizando el número de componentes para cada función y eligiendo los componentes de mayor calidad para cada función. La evaluación de la función de los componentes debería formar parte de toda estrategia de análisis de componentes.
Cantidad de componentes
Debe evaluarse el número de componentes de terceros y de código abierto en un proyecto. El coste operativo y de mantenimiento del uso del código abierto aumentará con la adopción de cada nuevo componente. El impacto puede ser significativamente mayor con los ecosistemas de micromódulos cuando hay cientos o miles de aplicaciones en un entorno determinado. Además del aumento de los costes operativos y de mantenimiento, cabe esperar una disminución de la capacidad de los equipos de desarrollo para mantener conjuntos crecientes de componentes a lo largo del tiempo. Esto es especialmente cierto para los equipos con limitaciones de tiempo.
Gestión de componentes
Si tenemos alojado un repositorio en GitHub y este es público se nos ofrece automáticamente un visor de dependencias en Insights-> Dependency Graph. En esta lista se muestran todas las dependencias de tu proyecto así como sus versiones.
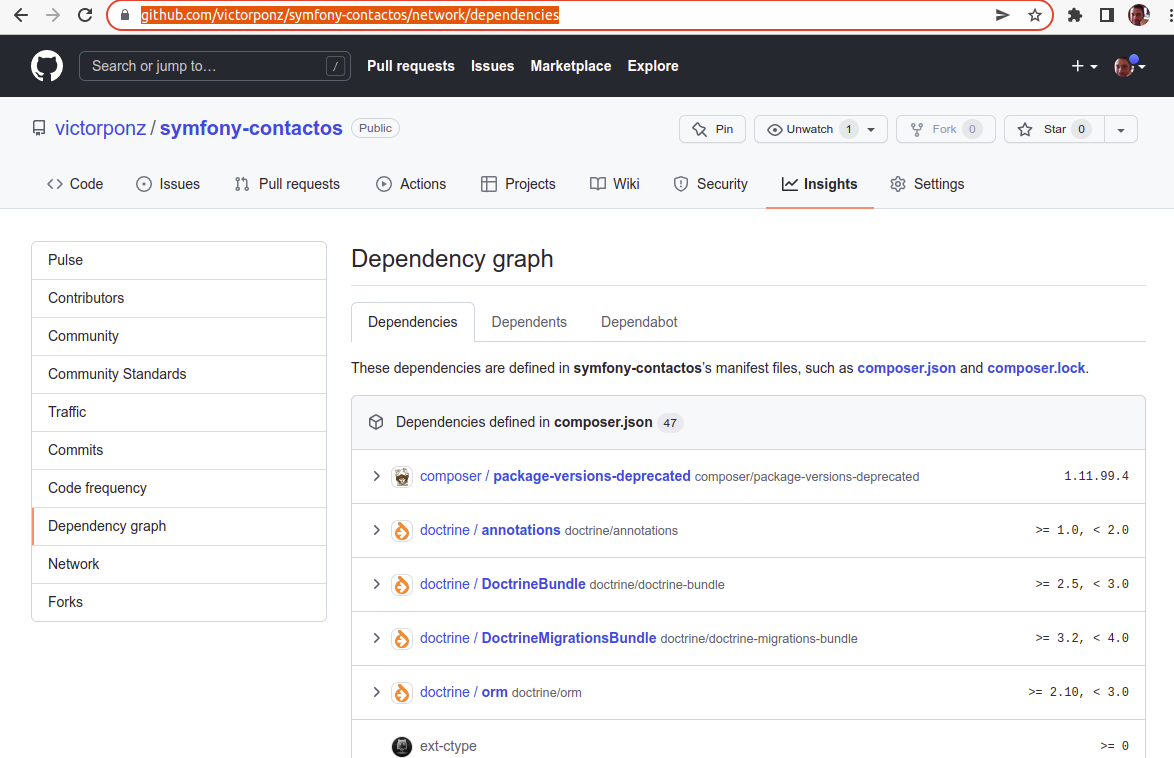
Pero existe una herramienta llamada https://docs.dependencytrack.org/ que, además de mostrar las dependencias también permite conocer sus vulnerabilidades.
Lista de materiales de software (SBOM)
Los gobiernos y la industria están tratando de definir la transparencia del software. Algunos de estos esfuerzos conducirán a un mayor cumplimiento de los requisitos reglamentarios. La transparencia del software se consigue a menudo mediante la publicación de la lista de materiales del software (Software List Of Materials). Una lista de materiales es sinónimo de la lista de ingredientes de una receta. Ambos son una forma de transparencia.
Existen múltiples estándares de SBOM, incluyendo OWASP CycloneDX y SPDX, cada uno con sus propios puntos fuertes y casos de uso para los que fueron diseñados. La evaluación de los estándares SBOM para determinar cuáles son aplicables a los requisitos de una organización debería formar parte de una estrategia general de C-SCRM.
DependencyTrack
DependencyTrack es un proyecto de la OWASP que permite una gestión de las dependencias y de sus vulnerabilidades.
Dependency-Track is an intelligent Component Analysis platform that allows organizations to identify and reduce risk in the software supply chain. Dependency-Track takes a unique and highly beneficial approach by leveraging the capabilities of Software Bill of Materials (SBOM). This approach provides capabilities that traditional Software Composition Analysis (SCA) solutions cannot achieve.
Dependency-Track monitorea el uso de componentes en todas las versiones de cada aplicación en su cartera para identificar proactivamente el riesgo en una organización. La plataforma tiene un diseño basado en API y es ideal para su uso en entornos de CI/CD.
Instalación
Se puede instalar directamente con docker-compose
1
2
3
4
5
# Downloads the latest Docker Compose file
curl -LO https://dependencytrack.org/docker-compose.yml
# Starts the stack using Docker Compose
docker-compose up -d
Una vez instalado y accedido, hemos de crear un proyecto y cargar un archivo bom.xml que es un formato estándar para especificar Bill Of Materials
Tenemos ejemplos de este tipo de archivos en https://github.com/CycloneDX/bom-examples/tree/master/SBOM
Una vez descargado uno de los ejemplos, hemos de subirlo mediante el botón Upload BOM
Se mostrará toda la información en una rejilla como la siguiente:
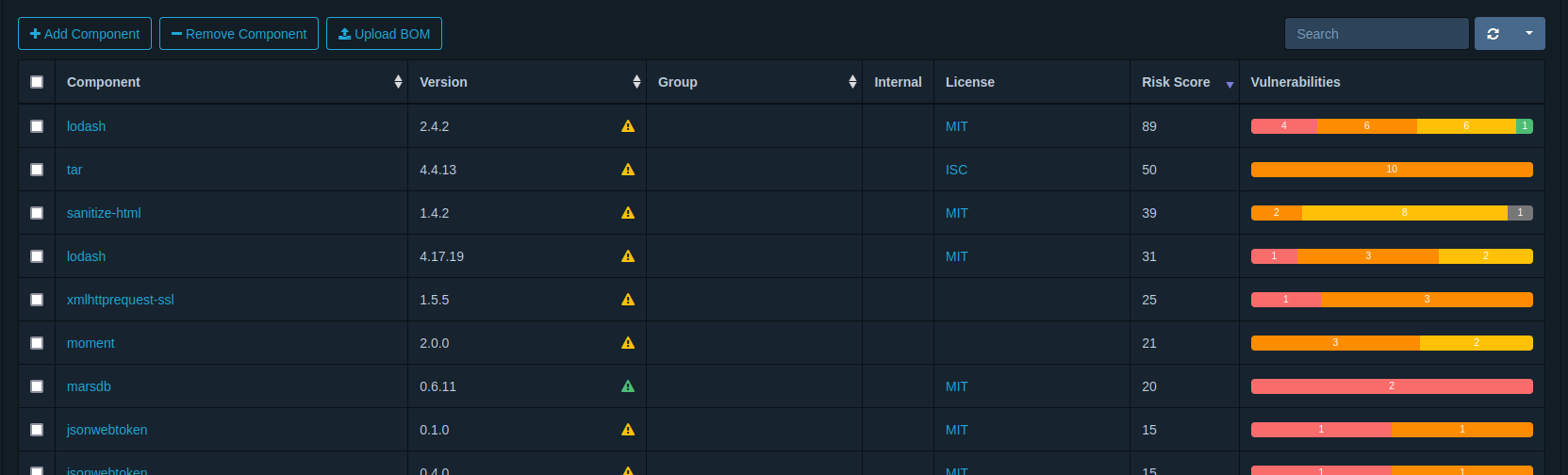
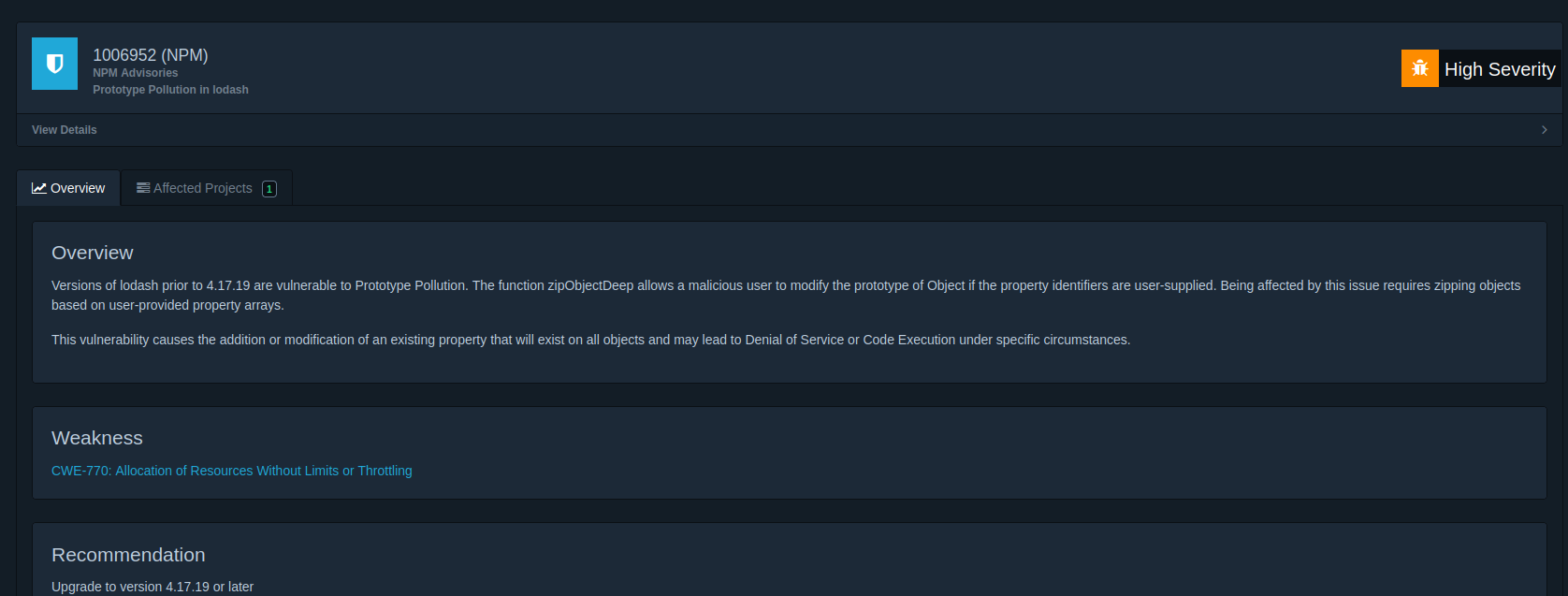
Si ordenamos por Risk Score vemos que la primera es lodash. Al hacer clic en ella, nos muestra más información.
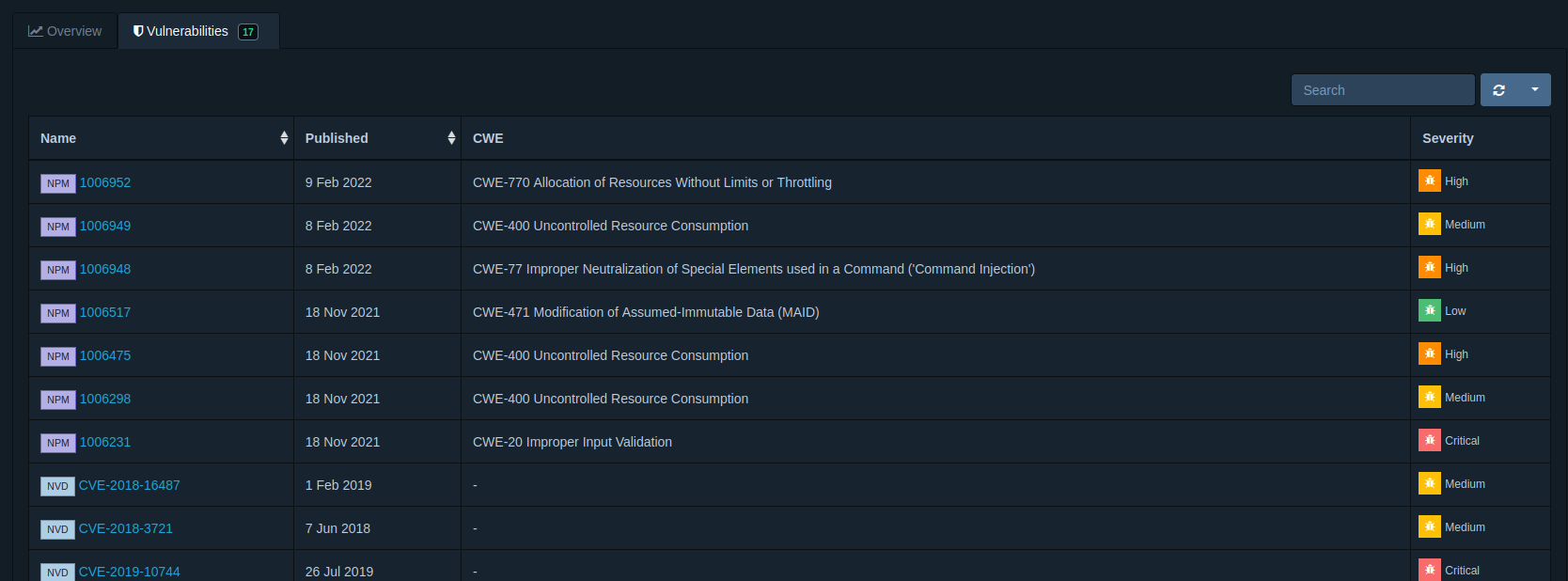
Donde además podemos acceder a la información detallada de cada una de las vulnerabilidades.
Generación de archivos BOM
Existen varias herramientas para generar automáticamente ficheros BOM a partir de la definición de un proyecto.
- Para node.js existe una librería llamada cyclonedx que permite generar ficheros BOM a partir de la definición del proyecto
- Para php existe la librería CycloneDX
- Para java también se pueden crear automáticamente a partir del fichero
pom.xml
Más información en https://owasp.org/www-community/Component_Analysis y https://owasp.org/www-project-dependency-track/