Ya hemos cubierto las dos fases más cruciales del proceso de entrega continua: la fase de compromiso y la prueba de aceptación automatizada. En este capítulo, nos centraremos en la gestión de la configuración, que conecta el entorno virtual en contenedores con la infraestructura del servidor real.
Este capítulo cubre los siguientes puntos:
- Introducción al concepto de gestión de la configuración
- Explicación de las herramientas de administración de configuración más populares
- Discutir los requisitos de Ansible y el proceso de instalación
- Uso de Ansible con comandos ad hoc
- Mostrando el poder de la automatización de Ansible con playbooks
- Explicación de las funciones de Ansible y Ansible Galaxy
- Implementación de un caso de uso del proceso de implementación
- Uso de Ansible junto con Docker y Docker Compose
Introducción a la gestión de la configuración
La gestión de la configuración es un proceso de control de los cambios de configuración de manera que el sistema mantenga la integridad a lo largo del tiempo. Aunque el término no se originó en la industria de TI, actualmente se usa ampliamente para referirse al software y al hardware. En este contexto, se refiere a los siguientes aspectos:
-
Configuración de la aplicación: esto implica propiedades de software que deciden cómo funciona el sistema, que generalmente se expresan en forma de banderas o archivos de propiedades que se pasan a la aplicación, por ejemplo, la dirección de la base de datos, el tamaño máximo de fragmento para el procesamiento de archivos o el nivel de registro. Se pueden aplicar durante diferentes fases de desarrollo: compilación, paquete, implementación o ejecución.
-
Configuración de la infraestructura: implica la configuración de la infraestructura y el entorno del servidor, que se ocupa del proceso de implementación. Define qué dependencias deben instalarse en cada servidor y especifica la forma en que se organizan las aplicaciones (qué aplicación se ejecuta en qué servidor y en cuántas instancias).
Veamos el diagrama que presenta cómo funciona la herramienta de administración de configuración.
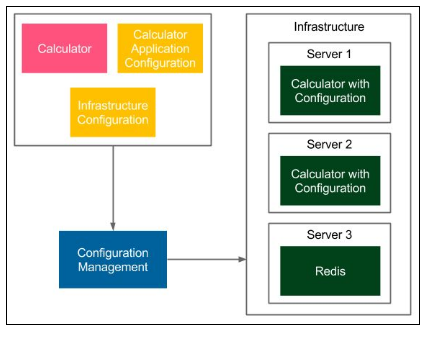
La herramienta de administración de configuración lee el archivo de configuración y prepara el entorno respectivamente (instala herramientas y bibliotecas dependientes, implementa las aplicaciones en varias instancias).
En el ejemplo anterior, la configuración de la infraestructura especifica que el servicio de la calculadora debe implementarse en dos instancias en el servidor 1 y el servidor 2 y que el servicio de Redis debe instalarse en el servidor 3. La configuración de la aplicación de la calculadora especifica el puerto y la dirección del servidor de Redis, para que los servicios puedan comunicarse.
La configuración puede diferir según el tipo de entorno (control de calidad, ensayo, producción), por ejemplo, las direcciones de los servidores pueden ser diferentes.
Hay muchos enfoques para la gestión de la configuración, pero antes de buscar soluciones concretas, comentemos qué características debe tener una buena herramienta de gestión de la configuración.
Características de una buena gestión de la configuración
¿Cómo debería ser la solución de gestión de configuración moderna? Repasemos los factores más importantes:
- Automatización: cada entorno debe ser reproducible automáticamente, incluido el sistema operativo, la configuración de la red, el software instalado y las aplicaciones implementadas. En tal enfoque, solucionar los problemas de producción no significa más que una reconstrucción automática del entorno. Además, eso simplifica las replicaciones del servidor y garantiza que los entornos de ensayo y producción sean exactamente iguales.
- Control de versiones: se debe realizar un seguimiento de cada cambio en la configuración, para que sepamos quién lo hizo, por qué y cuándo. Por lo general, eso significa mantener la configuración en el repositorio del código fuente, ya sea junto con el código o en un lugar separado. Se recomienda la primera solución porque las propiedades de configuración tienen un ciclo de vida diferente al de la propia aplicación. El control de versiones también ayuda a solucionar problemas de producción: la configuración siempre se puede revertir a la versión anterior y el entorno se puede reconstruir automáticamente. La única excepción a la solución basada en el control de versiones es el almacenamiento de credenciales y otra información confidencial; estos nunca deben registrarse.
- Cambios incrementales: la aplicación de un cambio en la configuración no debería requerir la reconstrucción de todo el entorno. Por el contrario, un pequeño cambio en la configuración debería cambiar solo la parte relacionada de la infraestructura.
- Aprovisionamiento de servidores: gracias a la automatización, agregar un nuevo servidor debería ser tan rápido como agregar su dirección a la configuración (y ejecutar un comando).
- Seguridad: El acceso tanto a la herramienta de gestión de configuración como a las máquinas bajo su control debe estar bien asegurado. Cuando se utiliza el protocolo SSH para la comunicación, el acceso a las claves o credenciales debe estar bien protegido.
- Simplicidad: todos los miembros del equipo deben poder leer la configuración, realizar cambios y aplicarlos al entorno. Las propiedades en sí también deben mantenerse lo más simples posible y las que no están sujetas a cambios es mejor mantenerlas codificadas.
Es importante tener en cuenta estos puntos al crear la configuración e, incluso antes, al elegir la herramienta de gestión de configuración adecuada.
Descripción general de las herramientas de gestión de la configuración
Las herramientas de administración de configuración más populares son Ansible, Puppet y Chef. Cada una de ellas es una buena elección; todos son productos de código abierto con versiones básicas gratuitas y ediciones empresariales de pago. Las diferencias más importantes entre ellos son:
- Idioma de configuración: Chef usa Ruby, Puppet usa su propio DSL (basado en Ruby) y Ansible usa YAML.
- Basado en agentes: Puppet y Chef usan agentes para la comunicación, lo que significa que cada servidor administrado debe tener una herramienta especial instalada. Ansible, por el contrario, no tiene agente y utiliza el protocolo SSH estándar para la comunicación.
La característica sin agente es una ventaja significativa porque implica la necesidad de instalar nada en los servidores. Además, Ansible está tendiendo rápidamente hacia arriba. Sin embargo, otras herramientas también se pueden utilizar con éxito para el proceso de Entrega Continua.
Instalación de Ansible
Ansible es un motor de automatización sin agentes de código abierto para el aprovisionamiento de software, la gestión de la configuración y la implementación de aplicaciones. Su primer lanzamiento fue en 2012 y su versión básica es gratuita tanto para uso personal como comercial. La versión empresarial, llamada Ansible Tower, proporciona administración y tableros de GUI, API REST, control de acceso basado en roles y algunas características más.
Presentamos el proceso de instalación y una descripción de cómo se puede usar por separado y junto con Docker.
Requisitos del servidor Ansible
Ansible utiliza el protocolo SSH para la comunicación y no tiene requisitos especiales con respecto a la máquina que administra. Tampoco hay un servidor maestro central, por lo que basta con instalar la herramienta cliente de Ansible en cualquier lugar y ya podemos usarla para gestionar toda la infraestructura.
El único requisito para las máquinas que se gestionan es tener instalada la herramienta Python y, obviamente, el servidor SSH. Sin embargo, estas herramientas casi siempre están disponibles de forma predeterminada en cualquier servidor.
La instalación se puede seguir desde aquí
Uso de Ansible
Para utilizar Ansible, primero debemos definir el inventario, que representa los recursos disponibles. Luego, podremos ejecutar un solo comando o definir un conjunto de tareas utilizando el playbook de Ansible.
Crear inventario
Un inventario es una lista de todos los servidores administrados por Ansible. Cada servidor requiere nada más que el intérprete de Python y el servidor SSH instalado. De forma predeterminada, Ansible asume que las claves SSH se utilizan para la autenticación; sin embargo, también es posible usar el nombre de usuario y la contraseña agregando la opción --ask-pass a los comandos de Ansible.
Las claves SSH se pueden generar con la herramienta
ssh-keygeny generalmente se almacenan en el directorio ~/.ssh . Una vez generadas se copian al host remoto mediante:
El inventario se define en el archivo /etc/ansible/hosts y tiene la siguiente estructura:
1
2
3
4
[group_name]
<server1_address>
<server2_address>
...
La sintaxis de inventario también acepta rangos de servidores, por ejemplo,
www[01-22].company.com. El puerto SSH también debe especificarse si es distinto de 22 (el predeterminado). Puedes leer más en la página oficial de Ansible en: https://docs.ansible.com/ansible/latest/user_guide/intro_inventory.html
Puede haber 0 o muchos grupos en el archivo de inventario. Como ejemplo, definamos dos máquinas en un grupo de servidores.
1
2
3
[webservers]
web1 ansible_host=192.168.0.241 ansible_user=admin
web2 ansible_host=192.168.0.242 ansible_user=admin
El archivo anterior define un grupo denominado webservers, que consta de dos servidores. El cliente de Ansible iniciará sesión como admin en ambos.
Comandos ad hoc
El comando más simple que podemos ejecutar es un ping en todos los servidores.
1
2
3
4
5
6
7
8
9
ansible all -m ping
web1 | SUCCESS => {
"changed": false,
"ping": "pong"
}
web2 | SUCCESS => {
"changed": false,
"ping": "pong"
}
Usamos la opción -m <module_name> , que permite especificar el módulo que debe ejecutarse en los hosts remotos. El resultado es exitoso, lo que significa que los servidores están accesibles y la autenticación está configurada correctamente.
Puede encontrar una lista completa de los módulos disponibles en Ansible en la página http://docs.ansible.com/ansible/modules.html. En este ejemplo se ejecuta el comando en todos los hosts pero también podríamos llamarlos por el nombre del grupo servidores web o por el alias de host único. Como segundo ejemplo, ejecutemos un comando de shell solo en uno de los servidores.
1
2
3
ansible web1 -a "/bin/echo hello"
web1 | SUCCESS | rc=0 >>
hello
La opción -a <arguments> especifica los argumentos que se pasan al módulo Ansible. En este caso, no especificamos el módulo, por lo que los argumentos se ejecutan como un comando de shell Unix. El resultado fue exitoso y se imprimió hello.
Si el comando ansible se conecta al servidor por primera vez (o se reinstala el servidor), se nos solicita el mensaje de confirmación de la clave (mensaje SSH cuando el host no está presente en
known_hosts). Dado que puede interrumpir una secuencia de comandos automatizada, podemos deshabilitar el mensaje de solicitud descomentandohost_key_checking = Falseen el archivo/etc/ansible/ansible.cfgo configurando la variable de entornoANSIBLE_HOST_KEY_CHECKING=False.
En su forma simple, la sintaxis del comando ad hoc de Ansible tiene el siguiente aspecto:
1
ansible <target> -m <module_name> -a <module_arguments>
El propósito de los comandos ad hoc es hacer algo rápidamente cuando no es necesario repetirlo. Por ejemplo, podemos querer verificar si un servidor está vivo o apagar todas las máquinas para las vacaciones de Navidad. Este mecanismo puede verse como la ejecución de un comando en un grupo de máquinas con la simplificación de sintaxis adicional proporcionada por los módulos. Sin embargo, el verdadero poder de la automatización de Ansible reside en los playbooks.
Playbooks
Un playbook de Ansible es un archivo de configuración que describe cómo deben configurarse los servidores. Proporciona una forma de definir una secuencia de tareas que deben realizarse en cada una de las máquinas. Un playbook se expresa en el lenguaje de configuración YAML, lo que lo hace legible por humanos y fácil de entender. Comencemos con un playbook de muestra y luego veamos cómo podemos usarlo.
Definición de playbook
Un playbook se compone de una o varias jugadas. Cada jugada contiene un nombre de grupo de host, tareas a realizar y detalles de configuración (por ejemplo, nombre de usuario remoto o derechos de acceso). Un playbook de ejemplo podría verse así:
1
2
3
4
5
6
7
8
- hosts: web1
become: yes
become_method: sudo
tasks:
- name: ensure apache is at the latest version
apt: name=apache2 state=latest
- name: ensure apache is running
service: name=apache2 state=started enabled=yes
Esta configuración contiene una jugada que:
-
Se ejecuta solo en el host web1
-
Obtiene acceso de root usando el comando
sudo -
Ejecuta dos tareas:
- Instalación de la última versión de apache2: el módulo
Ansible apt(llamado con dos parámetrosname=apache2 y state=latest) comprueba si el paquete apache2 está instalado en el servidor y, si no, utiliza la herramientaapt-getpara instalar apache2 - Ejecución del servicio apache2: el módulo Ansible
service(llamado con tres parámetros:name=apache2 state=started enabled=yes) verifica si el servicio está arrancado y si no lo está lo arranca
- Instalación de la última versión de apache2: el módulo
Mientras se dirige a los hosts, también puede usar patrones, por ejemplo, podríamos usar
web*para dirigirse tanto a web1 como a web2. Puede obtener más información sobre los patrones de Ansible en: https://docs.ansible.com/ansible/latest/user_guide/intro_patterns.html
Hay que tener en cuenta que cada tarea tiene un nombre legible por humanos, que se usa en la salida de la consola, de modo que apt y service son módulos de Ansible y name=apache2, state=latest y state=started son argumentos de módulo. Ya hemos visto módulos y argumentos de Ansible al usar comandos ad hoc. En el playbook anterior, definimos solo una jugada, pero puede haber muchas y cada una puede estar relacionada con diferentes grupos de anfitriones.
Por ejemplo, podríamos definir dos grupos de servidores en el inventario: base de datos y servidores web. Luego, en el playbook, podríamos especificar tareas que deberían ejecutarse en todas las máquinas que alojan bases de datos y algunas tareas diferentes que deberían ejecutarse en todos los servidores web. Al usar un comando, podríamos configurar todo el entorno.
Ejecutar el playbook
Cuando se ha definido un playbook.yml podemos ejecutarlo mediante:
1
ansible-playbook playbook.yml -K
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
BECOME password:
PLAY [web1] ********************************************************************
TASK [Gathering Facts] *********************************************************
ok: [web1]
TASK [ensure apache is at the latest version] **********************************
changed: [web1]
TASK [ensure apache is running] ************************************************
ok: [web1]
PLAY RECAP *********************************************************************
web1 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Si el servidor requiere ingresar la contraseña para el comando
sudo, entonces debemos agregar la opción--ask-sudo-passo-Kal comandoansible-playbook. También es posible pasar la contraseña de sudo (si es necesario) configurando la variable adicional-e ansible_become_pass=<sudo_password>.
Se ejecutó la configuración del playbook y, por lo tanto, se instaló e inició la herramienta apache2. Ten en cuenta que si la tarea cambió algo en el servidor, se marca como changed. Por el contrario, si no hubo cambio, se marca como ok.
Es posible ejecutar tareas en paralelo usando la opción `-f
Idempotencia de los playbooks
Si ejecutamos el playbook:
1
2
3
4
5
6
7
8
9
10
11
12
13
PLAY [web1] ********************************************************************
TASK [Gathering Facts] *********************************************************
ok: [web1]
TASK [ensure apache is at the latest version] **********************************
ok: [web1]
TASK [ensure apache is running] ************************************************
ok: [web1]
PLAY RECAP *********************************************************************
web1 : ok=3 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
La salida es ligeramente diferente. Esta vez el comando no cambió nada en el servidor. Esto se debe a que cada módulo de Ansible está diseñado para ser idempotente. En otras palabras, ejecutar el mismo módulo muchas veces en una secuencia debería tener el mismo efecto que ejecutarlo solo una vez.
La forma más sencilla de lograr la idempotencia es verificar siempre primero si la tarea aún no se ha ejecutado y ejecutarla solo si no se ha ejecutado. La idempotencia es una característica poderosa y siempre debemos escribir nuestras tareas de Ansible de esta manera.
Si todas las tareas son idempotentes, entonces podemos ejecutarlas tantas veces como queramos. En ese contexto, podemos pensar en el playbook como una descripción del estado deseado de las máquinas remotas. Luego, el comando ansible-playbook se encarga de llevar la máquina (o grupo de máquinas) a ese estado.
Handlers
Algunas operaciones deben ejecutarse solo si alguna otra tarea cambió. Por ejemplo, imagina que copias el archivo de configuración a la máquina remota y el servidor Apache debe reiniciarse solo si el archivo de configuración ha cambiado. ¿Cómo abordar un caso así?
Ansible proporciona un mecanismo orientado a eventos para notificar los cambios. Para usarlo, necesitamos saber dos palabras clave:
- handlers: Esto especifica las tareas ejecutadas cuando se notifica
- notify: Esto especifica los controladores que deben ejecutarse
Veamos un ejemplo de cómo podríamos copiar la configuración al servidor y reiniciar Apache solo si la configuración ha cambiado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- hosts: web1
become: yes
become_method: sudo
tasks:
- name: copy file
copy:
src: foo.conf
dest: /etc/foo.conf
notify:
- restart apache
handlers:
- name: restart apache
service:
name: apache2
state: restarted
Los controladores se ejecutan siempre al final del play y solo una vez, incluso si se desencadenan por múltiples tareas
Ahora, podemos crear el archivo foo.conf y ejecutar ansible-playbook:
1
2
touch foo.conf
ansible-playbook playbook.yml -K
Ansible copió el archivo y reinició el servidor Apache. Es importante entender que si ejecutamos el comando nuevamente, no pasará nada. Sin embargo, si cambiamos el contenido del archivo foo.conf y luego ejecutamos el comando ansible-playbook, el archivo será copiado de nuevo y apache reiniciado:
1
2
echo "something" > foo.conf
ansible-playbook playbook.yml
Utilizamos el módulo de copy, que es lo suficientemente inteligente como para detectar si el archivo ha cambiado y, en tal caso, realizar un cambio en el servidor.
Variables
Si bien la automatización de Ansible hace que las cosas sean idénticas y repetibles para múltiples hosts, es inevitable que los servidores requieran algunas diferencias. Por ejemplo, piensa en el número de puerto de la aplicación. Puede ser diferente dependiendo de la máquina. Afortunadamente, Ansible proporciona variables, que es un buen mecanismo para lidiar con las diferencias de servidor. Vamos a crear un nuevo playbook y definir una variable.
1
2
3
4
5
6
7
- hosts: web1
vars:
http_port: 8080
tasks:
- name: print port number
debug:
msg: "Port number: {{http_port}}"
La configuración define la variable http_port con el valor 8080 y se usa mediante la sintaxis Jinja2.
El módulo de debug imprime el mensaje mientras se ejecuta. Si ejecutamos el comando ansible-playbook, podemos ver el uso de la variable.
1
2
3
4
5
*
ok: [web1] => {
"msg": "Port number: 8080"
}
Además de las variables definidas por el usuario, también existen variables automáticas predefinidas. Por ejemplo, la variable hostvars almacena un mapa con la información de todos los hosts del inventario. Usando la sintaxis de Jinja2, podemos iterar e imprimir las direcciones IP de todos los hosts en el inventario.
1
2
3
4
5
6
- hosts: web1
tasks:
- name: print IP address
debug:
msg: "{% for host in groups['all'] %} {{
hostvars[host]['ansible_host'] }} {% endfor %}"
Ten en cuenta que con el uso del lenguaje Jinja2, podemos especificar las operaciones de control de flujo dentro del archivo del playbook de Ansible.
Ansible Galaxy
Ansible Galaxy es para Ansible lo que Docker Hub es para Docker: almacena roles comunes para que otros puedan reutilizarlos. Puede explorar los roles disponibles en la página de Ansible Galaxy en: https://galaxy.ansible.com/
Para instalar el rol desde Ansible Galaxy, podemos usar el comando ansible-galaxy.
1
ansible-galaxy install username.role_name
Este comando descarga automáticamente el rol. En el caso del ejemplo de MySQL, podríamos descargar el rol ejecutando:
1
ansible-galaxy install geerlingguy.mysql
El comando descarga el rol de mysql, que luego se puede usar en el archivo el playbook.
1
2
3
4
- hosts: database
roles:
- role: geerlingguy.mysql
become: yes